初探PySpark
将介绍PySpark的单机与集群配置方法,以及基本使用示例。
Apache Spark是一个闪电般快速的实时处理框架。它进行内存计算以实时分析数据。由于 Apache Hadoop MapReduce 仅执行批处理并且缺乏实时处理功能,因此它开始出现。因此,引入了Apache Spark,因为它可以实时执行流处理,也可以处理批处理。
除了实时和批处理之外,Apache Spark还支持交互式查询和迭代算法。Apache Spark有自己的集群管理器,可以托管其应用程序。它利用Apache Hadoop进行存储和处理。它使用 HDFS (Hadoop分布式文件系统)进行存储,它也可以在 YARN 上运行Spark应用程序。
PySpark是通过python库使用Spark的工具。
前提条件
- anaconda
- 下载并安装好jdk 1.8 (PySpark与Java9及以上尚不兼容)
单机安装与配置
推荐使用anaconda虚拟python环境安装PySpark。以Mac用户为例。
1 | cd anaconda3 |
在pyspark.yml中写入以下内容(注意:'-'符号前必须为两个空格):
1 | name: pyspark |
新建PySpark虚拟环境:
1 | conda env create -f pyspark.yml |
确认安装:
1 | conda env list |
单机应用示例
SparkContext是任何spark功能的入口点。当我们运行任何Spark应用程序时,启动一个驱动程序,它具有main函数,并在此处启动SparkContext。然后,驱动程序在工作节点上的执行程序内运行操作。
SparkContext使用Py4J启动 JVM 并创建 JavaSparkContext。默认情况下,PySpark将SparkContext作为 'sc'提供 ,因此创建新的SparkContext将不起作用。[2]
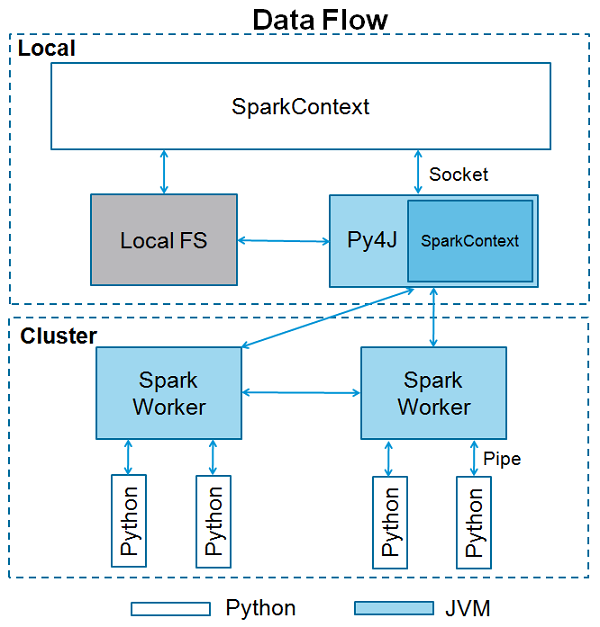
以下是单机示例代码,
1 | from pyspark import SparkConf |
集群安装与配置
需要在各个集群节点上安装Spark[4]。
安装Spark
在 下载页面下载Spark
下载到的文件以spark-2.4.5-bin-hadoop2.7.tgz为例(需要jdk1.8),解压
1
2tar xzvf spark-2.4.5-bin-hadoop2.7.tgz
export SPARK_HOME=/xxx/xxx/spark-2.4.5 # 可以添加到bashrc中将SPARK_HOME/conf/spark-env.sh.template 复制一份重新命名为spark-env.sh
1
2
3mkdir -p /tmp/spark_logs
cd SPARK_HOME/conf/
vim spark-env.shmaster节点和slave节点的spark-env.sh均填入以下配置:
1
2
3
4SPARK_MASTER_HOST='192.168.0.102'
export SPARK_LOG_DIR=/tmp/spark_logs
export PYSPARK_PYTHON=/usr/bin/python3 # 指向你的pyspark环境的python
export PYSPARK_DRIVER_PYTHON=/usr/bin/ipython # 指向你的pyspark环境的ipython启动master
1
2cd SPARK_HOME/sbin
./start-master.sh将会看到类似以下输出:
1
2~$ ./start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /tmp/spark_logs/spark-arjun-org.apache.spark.deploy.master.Master-1-arjun-VPCEH26EN.out启动slave
1
./start-slave.sh spark://<your.master.ip.address>:7077
将会看到类似以下输出:
1
starting org.apache.spark.deploy.worker.Worker, logging to /tmp/spark_logs/spark-experiment-org.apache.spark.deploy.worker.Worker-1-slave026.out
集群应用实例
1 | from pyspark import SparkConf |
参考
[1] https://www.guru99.com/pyspark-tutorial.html
[2] http://codingdict.com/article/8880
[3] https://blog.csdn.net/qq_23860475/article/details/90476197
[4] https://www.tutorialkart.com/apache-spark/how-to-setup-an-apache-spark-cluster/