Hadoop的安装与配置
介绍Hadoop的伪分布式和集群安装与配置。
前提
- JDK1.8
下载
Hadoop下载地址,下面以hadoop-2.7.7.tar.gz为例
创建用户(可选)
官方推荐:
- 创建一个
hadoop用户和一个hadoop组 - 创建三个用户
hdfs、mapred、yarn,均属于hadoop组hdfs用来运行HDFSmapred用来运行MapReduceyarn用来运行YARN
本文中直接使用了已有用户。
伪分布式(单机)安装
1.
解压hadoop-2.7.7.tar.gz到/opt下:
1
tar xzvf hadoop-2.7.7.tar.gz -C /opt
2.
配置~/.bashrc中添加环境变量:
1
2export HADOOP_HOME=/opt/hadoop-2.7.7
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source ~/.bashrc生效。
3. 配置SSH
因为Hadoop的一些管理脚本会通过ssh登录到其他节点上面去执行一些命令,所以需要集群内可以相互免密登录(YARN和HDFS)。虽然我们是单台服务器,但还是需要执行ssh localhost命令时不需要输入密码[2]。配置方式如下:
1
2
3
4 伪分布式模式,ssh localhost 需要给自己做免密登陆
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
如果是多用户安装,需要在hdfs和yarn下均执行这三条命令。
4. HDFS配置
在$HADOOP_HOME/etc/hadoop/hadoop-env.sh中找到注释掉的JAVA_HOME,取消注释并配置为你的JDK路径:
1
export JAVA_HOME=/opt/jdk1.8.0_144
在$HADOOP_HOME/etc/hadoop/core-site.xml中配置如下内容(配置HDFS文件系统的URI):
1
2
3
4
5
6<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
在$HADOOP_HOME/etc/hadoop/hdfs-site.xml中配置如下内容(因为是单机,所以配置HDFS的复制数设置为1,即不复制,默认是3):
1
2
3
4
5
6<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
其它配置:
- Hadoop默认会把数据存储在
/tmp/hadoop-${user.name}目录下,涉及的两个配置项为:hadoop.tmp.dir和dfs.datanode.data.dir:hadoop.tmp.dir默认值为/tmp/hadoop-${user.name},在core-site.xml设置dfs.datanode.data.dir默认值为file://${hadoop.tmp.dir}/dfs/data,在hdfs-site.xml中设置
- Hadoop日志目录默认在
$HADOOP_HOME/logs中,可通过HADOOP_LOG_DIR修改
配置完成后,第一次使用先格式化HDFS文件系统:
1
2
3HADOOP_HOME/bin/hdfs namenode -format
如果已经把$HADOOP_HOME/bin放到path中的话,可以直接执行:
hdfs namenode -format
会输出类似以下信息:
1
2
3
4
520/03/31 09:17:58 INFO util.ExitUtil: Exiting with status 0
20/03/31 09:17:58 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at slave019/192.168.100.29
************************************************************/
5. Hadoop的启动与停止
Hadoop的所有操作命令和控制脚本分别在以下两个目录下面:
$HADOOP_HOME/bin: 都是shell命令,比如hdfs、hadoop、yarn......$HADOOP_HOME/sbin: 都是控制脚本,比如start-dfs.sh、start-dfs.cmd、stop-dfs.sh......- 常用脚本:
- 新版本中
start-all.sh和stop-all.sh脚本已经不推荐使用了,后续版本也可能废弃掉 - 主要使用
start-dfs.sh、stop-dfs.sh来启动和停止HDFS,使用start-yarn.sh和stop-yarn.sh来启动和停止YARN。
- 新版本中
- 常用脚本:
执行start-dfs.sh来启动HDFS:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 ./start-dfs.sh
出现类似以下输出
Starting namenodes on [localhost]
localhost: starting namenode, logging to $HADOOP_HOME/logs/hadoop-xxxxx-namenode-slave019.out
localhost: starting datanode, logging to $HADOOP_HOME/logs/hadoop-xxxxx-datanode-slave019.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to $HADOOP_HOME/logs/hadoop-xxxxx-secondarynamenode-slave019.out
使用jps命令来查看进程
jps
23888 Jps
23581 SecondaryNameNode <-- HDFS的
23133 NameNode <-- HDFS的
23325 DataNode <-- HDFS的
停止HDFS
./stop-dfs.sh
Stopping namenodes on [localhost]
localhost: stopping namenode
localhost: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
执行start-yarn.sh启动YARN:
1
2
3
4
5
6
7
8
9 ./start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to $HADOOP_HOME/logs/yarn-xxxxx-resourcemanager-slave019.out
localhost: starting nodemanager, logging to $HADOOP_HOME/logs/yarn-xxxxx-nodemanager-slave019.out
使用jps命令来查看进程
jps
25541 Jps
25064 ResourceManager
25401 NodeManager
6. 创建用户目录
经过前面几步,已经搭建了基本的Hadoop集群,如果需要让其它用户也可以访问系统,需要对每个用户创建一个家目录,并赋予权限,参考如下命令(注意需要先启动HDFS):
1 | hadoop fs -mkdir -p /user/root |
7. 验证
验证一下集群基本功能是否正常,先确保执行了:
start-dfs.shstart-yarn.sh
jps命令查看进程是否存在:
1
2
3
4
5
6
7 jps
26164 NameNode --> HDFS的
26359 DataNode --> HDFS的
25064 ResourceManager <-- yarn的
26616 SecondaryNameNode --> HDFS的
25401 NodeManager <-- yarn的
27114 Jps
HDFS启动后,Namenode默认监听50070端口,我们可以通过浏览器去访问http://<你的IP>:50070:
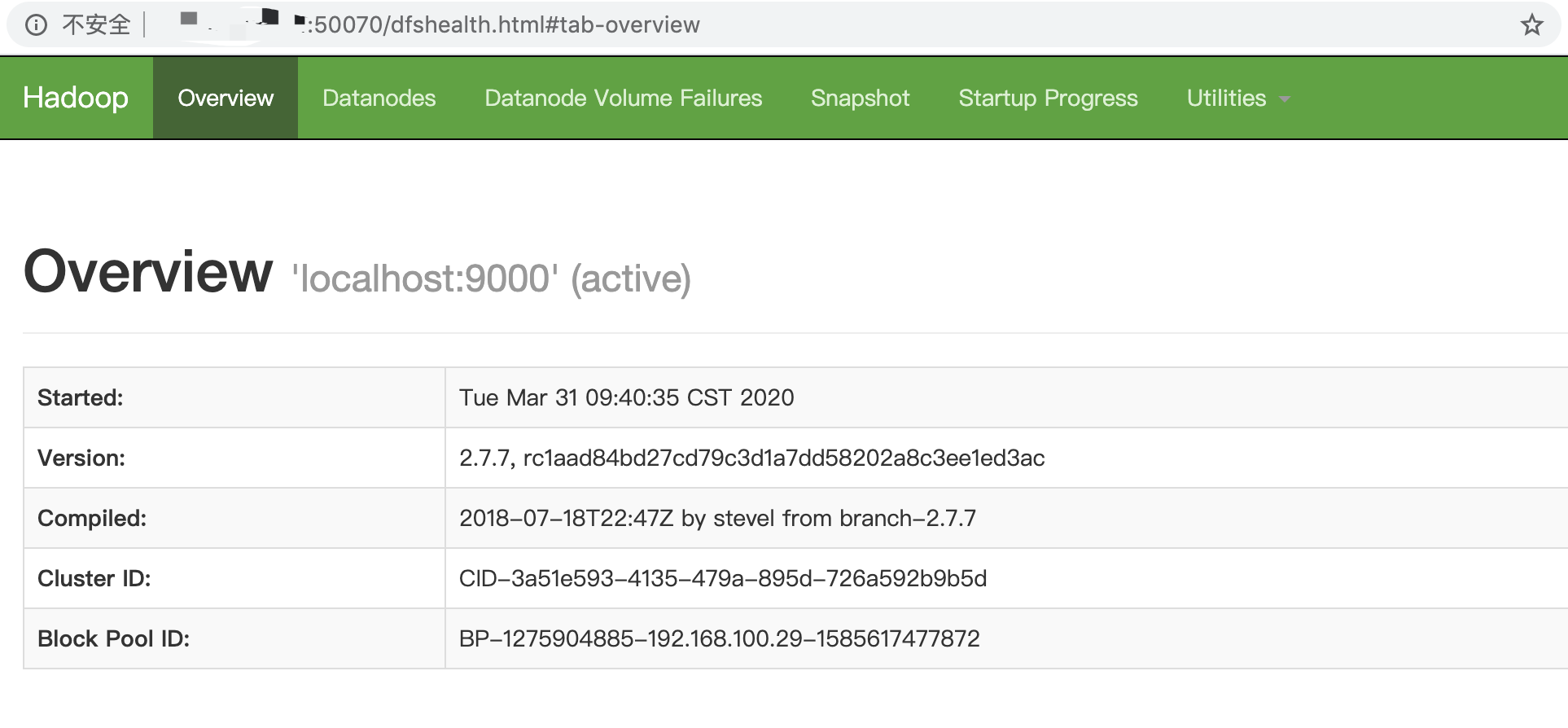
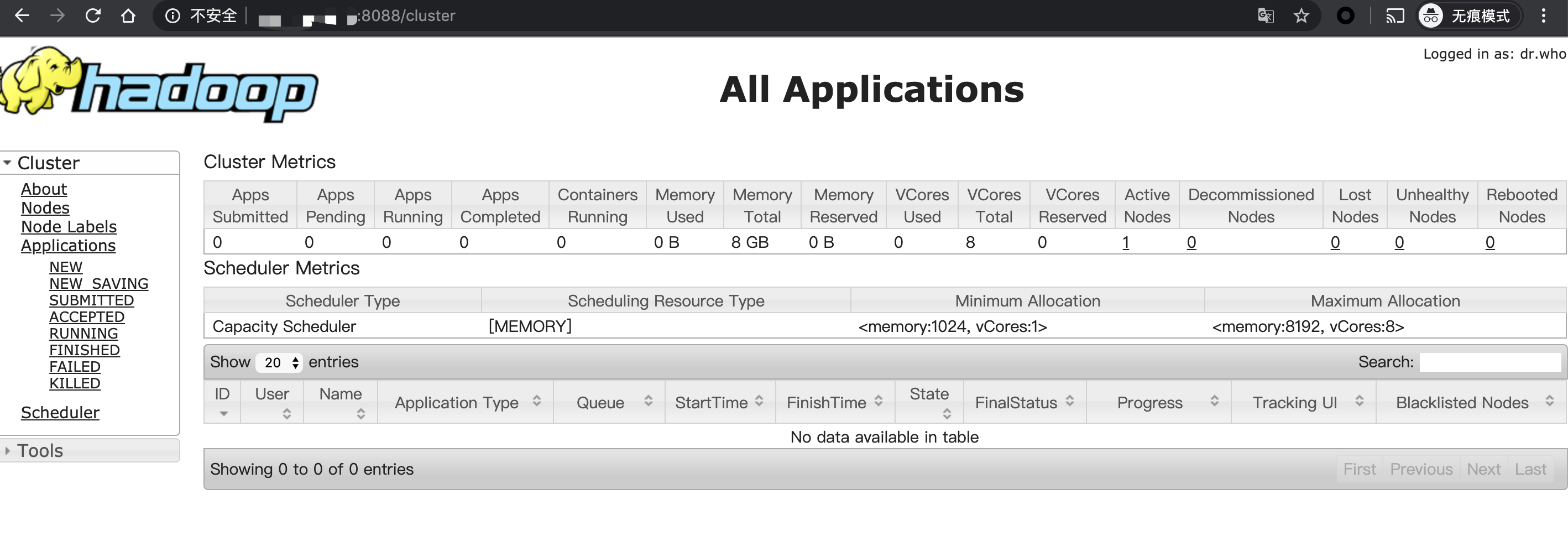
访问yarn,默认YARN监听8088,我们可以访问http://<你的IP>:8088查看::
运行测试程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23 进入Hadoop安装目录
cd $HADOOP_HOME/
拷贝例子用到的文件
bin/hdfs dfs -put etc/hadoop input
执行安装包里面带的例子程序(注意改成你自己下载的版本号)
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar grep input output 'dfs[a-z.]+'
查看执行结果
bin/hdfs dfs -get output output
cat output/*
类似以下输出
6 dfs.audit.logger
4 dfs.class
3 dfs.logger
3 dfs.server.namenode.
2 dfs.audit.log.maxbackupindex
2 dfs.period
2 dfs.audit.log.maxfilesize
1 dfs.log
1 dfs.file
1 dfs.servers
1 dfsadmin
1 dfsmetrics.log
1 dfs.replication
Hadoop集群搭建
先把1个节点的hadoop装好后,然后依次拷贝到其它节点上。
配置从master到所有slave的免密登陆
编辑
$HADOOP_HOME/etc/hadoop/slaves:1
2
3
4vi slaves #里面内容是:
slave01
slave02
slave03编辑
$HADOOP_HOME/etc/hadoop/core-site.xml:1
2
3
4
5
6
7
8
9
10
11<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://<master的hostname>:9000</value>
</property>
</configuration>编辑
$HADOOP_HOME/etc/hadoop/hdfs-site-xml:1
2
3
4
5
6
7
8
9
10
11
12
13
14<configuration>
<property>
<name>dfs.replication</name>
<value>3</value> <!--一般是3副本-->
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/xxxxx/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/xxxxx/hdfs/datanode</value>
</property>
</configuration>编辑
$HADOOP_HOME/etc/hadoop/mapred-site.xml:1
2
3
4
5
6<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>编辑
$HADOOP_HOME/etc/hadoop/yarn-site.xml:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>配置好后将hadoop文件夹复制到各个slave节点上,最好保证
HADOOP_HOME都一致。首次启动需要:
1
hdfs namenode -format #首次运行需要执行初始化,之后不需要
踩坑记录
- 每次修改完
core-site.xml和hdfs-site.xml后需执行:hdfs namenode -format,不然Namenode起不来,访问不了50070端口。 - master和slave的
HADOOP_HOME不一样的话,参考这个回答stack overflow(尽量保持HADOOP_HOME一致,说不定会有奇怪的问题)。 - 在HDFS集群运行时,不小心执行了
hdfs namenode -format,日志中报错"Incompatible clusterIDs in /data/xxxxx/hdfs/datanode",导致Datanode重启不了,参考了这个链接 删除了/data/xxxxx/hdfs/datanode才解决。 - 更改
$HADOOP_HOME/etc/hadoop/slaves后,需要重新复制到所有从节点上。
参考
[1] https://blog.csdn.net/u014552678/article/details/78584998
[2] https://niyanchun.com/hadoop-cluster-deploy.html